1. 딥러닝 소개
📌환영합니다!(C1W1L01)
인공지능은 새로운 전기⚡
오래 전 전기는 무수한 산업적 변화를 일으킴(운송, 제조업, 보건, 의사소통 등)
인공지능은 오래 전의 전기와 마찬가지로, 우리 사회에 매우 큰 영향을 미칠 것으로 예상됨.
이에 따라 딥러닝은 과학 기술 사회에서 가장 필요한 능력 중 하나가 되었음.
배울 내용
첫 번째 코스: 신경망과 딥러닝의 기초(고양이 인식 실습)
두 번째 코스: 딥러닝의 실제적인 면(신경망 실제 작동, 하이퍼파라미터 튜닝, 규제 등)
세 번째 코스: 머신러닝 프로젝트 설계 방식
네 번째 코스: CNN(합성곱 신경망) >> 주로 이미지에 적용
다섯 번째 코스: 자연어 처리, 시퀀스 모델, 순환 신경망(RNN)
📌신경망이란 무엇인가?(C1W1L02)
핵심 키워드: 신경망(Neural Network)
딥러닝이라는 용어는 신경망을 학습시키는 것을 칭함. 종종 아주 큰 신경망을 학습시키기도 함.

주택 가격 예측을 예시로 들면,
6개의 주택 데이터를 가지고 있다고 했을 때 주택 크기, 가격을 알 때 주택 가격을 예측하는 직선을 만든다고 가정함.
선형 회귀 모델을 알면 이 데이터에 직선을 그냥 그리자고 할 수 있음. (앞부분은 0으로 설정, 음수X)
이를 간단한 신경망으로 생각해보면
가장 쉬운 신경망은 X라고 불릴 주택의 크기가 신경망의 입력이 되고, 이는 작은 원인인 노드로 들어가며 Y라고 불릴 주택 가격으로 출력됨. 이 작은 원이 신경망에서는 하나의 뉴런이 되며 방금 그린 함수를 구현하게 됨. 뉴런이 하는 일은 주택의 크기를 입력받아 선형 함수를 계산하고, 결과 값과 0 중 큰 값을 주택의 가격으로 예측하는 것임.
신경망 논문에서는 이처럼 0으로 유지되다가 직선으로 올라가는 형식의 함수를 많이 보게 될 것. 이는 ReLU(Rectified Linear Unit)함수라고 불리며 rectify는 0과 결과값 중 큰 값을 취하라는 의미임.
더 큰 신경망은 더 많은 뉴런들로 이루어져 있으며 이들을 쌓은 모양임.
뉴런 하나하나를 한 레고 블럭으로 생각하고, 많은 레고 블럭들을 쌓음으로써 더 큰 신경망을 만들 수 있음.

또 다른 예시를 보자면,
주택의 크기에서 주택의 가격을 예측하는 대신에 다른 특성이 있다고 가정.
그 중 하나가 가족의 크기인데, 평방 미터, 피트 제곱, 침실 수 등은 가족의 크기에 적당한지를 결정함.
또한 우편번호를 알고있고 이를 통해 괜찮은 동네인지 파악할 수 있음(근처에 편의시설, 학교 등 여부)
재력은 명문 학군의 학교들이 있는지 알려주는 척도가 됨.
이 작은 원들은 ReLu 유닛일 수 있고 다른 비선형 함수일지도 모름.
집의 크기와 침실의 개수는 가족의 크기를, 우편번호와 재력은 학교의 질을 예측할 수 있게 해줌.
마지막으로 사람들이 얼마를 지불할 용의가 있는지 결정하는 것이 진짜 알고 싶은 정보이고, 앞서 말했던 특성들이 가격 예측에 도움을 줄 것.
이 예시에서 X는 4개의 입력(크기, 침실 수, 우편번호, 재력)들이고 y는 예측하고자 하는 값인 가격임.
이렇게 뉴런이나 간단한 예측기들을 쌓아 올림으로 이전보다 더 큰 신경망을 가지게 되었음.
하지만 입력X와 출력Y 사이에 있는 요인들은 스스로 알아내는 것일까?
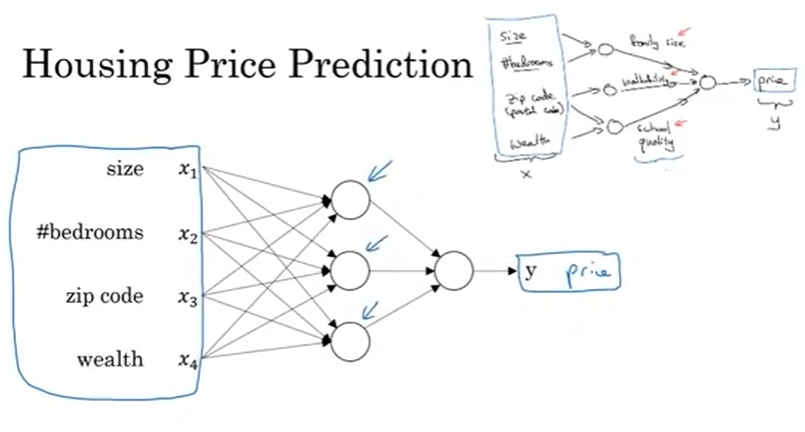
우리가 실제로 구현하는 것은 위와 같은 신경망과 같음.
4개의 입력을 가진 신경망들을 가지고 가격 Y를 예측하며, 중간에 있는 각 원들은 은닉 유닛이라고 불리고 각각의 은닉 유닛은 4개의 입력을 받음. 모든 입력 특성들은 중앙에 있는 원 모두에 연결되어 있기 때문에, 입력과 은닉 유닛은 서로 밀접하게 연관되어있음. 충분한 양의 x와 y를 훈련 예제로 준다면 신경망은 x를 y로 연결하는 함수를 알아내는데 뛰어난 성능을 보일 것.
📌신경망을 이용한 지도학습(C1W1L03)
핵심 키워드: 지도 학습(Supervised Learning), 입력(Input), 출력(Output), 구조적 데이터(Structured Data), 비구조적 데이터(Unstructured Data)

지도학습에서는 입력X와 출력Y에 매핑되는 함수를 학습하려 함.
위의 주택 가격 예측을 예시로 들었을 때, 입력은 주택에 관한 특성들이고 출력으로 가격 Y를 예측하고자 함.
또한 다음과 같이 신경망에서 지도학습을 잘 사용한 예시들이 있음:
- 온라인 광고 회사(광고 클릭 예측)
- 컴퓨터 비전(이미지, 사진 태깅)
- 음성 인식(텍스트 대본 출력)
- 기계 번역
- 자율주행
이처럼 신경망들을 통한 많은 값들의 생성은 어떤 문제를 해결하기 위한 적절한 X와 Y를 통해 이루어짐.

Standard NN (표준 신경망)
Convolutional NN (합성곱 신경망) >> 이미지 데이터에 강
Recurrent NN (순환 신경망) >> 1차원 시퀀스 데이터에 강함(+시간적 요소)

Structured Data(구조적 데이터): 기본적으로 데이터베이스로 표현된 데이터. 각 데이터들을 열로 가진 데이터베이스를 말함. 정리가 잘 되어있음.
Unstructured Data(비구조적 데이터): 음성파일이나 이미지, 텍스트 데이터 등. 여기서 특성은 이미지의 경우에 픽셀값, 텍스트의 각 단어 같은 것이 됨.
역사적으로 비구조적 데이터가 구조적 데이터보다 작업하기 훨씬 어려움.
하지만 딥러닝의 발전으로, 신경망 덕분에 컴퓨터들이 비구조적 데이터들을 해석하는 것이 근 몇년 전에 비해 굉장히 많이 발전함.
이 발전은 음성 인식이나 이미지 인식, 텍스트의 자연어 처리와 같은 흥미로운 응용분야에 많은 기회를 만들어 냈음.
📌왜 딥러닝이 뜨고 있을까요?(C1W1L04)
핵심 키워드: 데이터 크기(Scale of Data), 컴퓨터 성능 향상(Computation), 알고리즘(Algorithm)

가로축은 어떤 태스크에 대한 데이터의 양(데이터 레이블, 즉 입력값 X와 레이블 Y가 같이 있는 훈련 세트)을, 세로축은 학습 알고리즘의 성능을 나타냄.
전통적인 학습 알고리즘의 성능은 빨간색 그래프와 같음. 데이터를 추가하는 동안 성능이 향상되지만, 어느정도 시간이 지나면 성능이 정체기에 이르게 됨.
반면 신경망으로 작은 신경망을 훈련시켰을 때는 노란색 그래프와 같은 성능을 보이고,
조금 더 큰 중간 크기의 신경망을 훈련시키면 파란색과 같이 더 좋은 성능을 나타냄.
즉 신경망이 클수록 성능은 계속해서 좋아짐.
이렇게 아주 높은 성능을 발휘하기 위해서는 두 가지가 필요함.1. 충분히 큰 신경망(=많은 은닉 유닛, 많은 연결, 많은 파라미터)2. 충분히 많은 데이터(훈련 세트의 크기: m)단 훈련이 너무 오래 걸려서는 안 됨.훈련 데이터가 많지 않을 경우에는 구현 방법에 따라 성능이 결정되기도 함(알고리즘의 상대적 순위가 잘 정의되어 있지 않음). 반면 훈련 세트가 아주 클 때, 큰 신경망이 일관되게 압도적임을 확인할 수 있음.
초창기 딥러닝의 문제는 데이터와 계산의 규모였음. CPU나 GPU에서 아주 큰 신경망을 훈련시키게 된 것만으로 큰 성과를 낼 수 있었으며, 특히 최근 몇 년 간 알고리즘 자체에도 큰 혁신이 있었음. 놀랍게도 알고리즘 혁신의 많은 부분이 신경망을 더 빠르게 실행하는 데 관한 것이었음.
예를 들어 신경망의 큰 발전을 야기한 것 중 하나는 시그모이드 함수에서 ReLU 함수로 바뀌게 된 것이며, 이는 경사 하강법이라는 알고리즘을 훨씬 빠르게 만들었음. 이처럼 알고리즘 처리 시간을 빠르게 하면, 많은 데이터를 가진 큰 신경망을 적당한 시간 내에 처리할 수 있음.
빠른 계산이 중요한 또 다른 이유는, 많은 경우 신경망을 학습시키는 과정이 매우 반복적이기 때문임. 만약 신경망 학습에 오랜 시간이 걸린다면 이 주기 또한 오래 걸릴 것이고, 이는 생산성에 큰 차이를 줌. 효율적인 신경망을 만들고 과정을 빨리 반복하여 아이디어를 더 빨리 발전시킬 수 있도록 하는 것임.
'Project > DL 스터디&프로젝트' 카테고리의 다른 글
| [Euron 중급 세션 5주차] 딥러닝 2단계 1. 머신러닝 어플리케이션 설정하기 (0) | 2023.10.09 |
|---|---|
| [Euron 중급 세션 4주차] 5. 심층 신경망 네트워크 (1) | 2023.10.02 |
| [Euron 중급 세션 3주차] 4. 얕은 신경망 네트워크 (0) | 2023.09.25 |
| [Euron 중급 세션 2주차] 3. 파이썬과 벡터화 (0) | 2023.09.18 |
| [Euron 중급 세션 1주차] 2. 신경망과 로지스틱 회귀 (1) | 2023.09.11 |



